









змест
Час ад часу карыстальнікам Excel неабходна генераваць выпадковыя лікі, каб выкарыстоўваць іх у формулах або для іншых мэтаў. Для гэтага ў праграме прадугледжаны цэлы арсенал магчымасцяў. Выпадковыя лікі можна ствараць рознымі спосабамі. Прывядзём толькі тыя, якія паказалі сябе на практыцы найлепшым чынам.
Функцыя выпадковых лікаў у Excel
Дапусцім, у нас ёсць набор дадзеных, які павінен утрымліваць элементы, абсалютна не звязаныя адзін з адным. У ідэале яны павінны фарміравацца па законе нармальнага размеркавання. Для гэтага трэба выкарыстоўваць функцыю выпадковых лікаў. Ёсць дзве функцыі, з дапамогай якіх вы можаце дасягнуць сваёй мэты: РАЗЛІК и МІЖ СПРАВАЮ. Давайце больш падрабязна разгледзім, як іх можна выкарыстоўваць на практыцы.
Выбар выпадковых лікаў з дапамогай RAND
Гэтая функцыя не дае ніякіх аргументаў. Але, нягледзячы на гэта, ён дазваляе наладзіць дыяпазон значэнняў, у межах якога ён павінен генераваць выпадковы лік. Напрыклад, каб атрымаць яго ў рамках адзін да пяці, нам трэба выкарыстоўваць наступную формулу: =ЛІЧК()*(5-1)+1.

Калі гэтая функцыя размеркавана па іншых ячэйках з дапамогай маркера аўтазапаўнення, то мы ўбачым, што размеркаванне раўнамернае.
Падчас кожнага разліку выпадковага значэння, калі вы зменіце любую ячэйку ў любым месцы аркуша, лічбы будуць аўтаматычна згенераваны зноў. Такім чынам, гэтая інфармацыя не будзе захоўвацца. Каб пераканацца, што яны застаюцца, вы павінны ўручную запісаць гэтае значэнне ў лікавым фармаце або скарыстацца гэтай інструкцыяй.
- Робім клік па вочку, якая змяшчае выпадковы лік.
- Робім клік па радку формул, а затым выбіраем яго.
- Націсніце кнопку F9 на клавіятуры.
- Завяршаем гэтую паслядоўнасць дзеянняў націскам клавішы Enter.
Давайце праверым, наколькі раўнамерна размеркаваны выпадковыя лікі. Для гэтага нам трэба выкарыстоўваць гістаграму размеркавання. Каб зрабіць гэта, выканайце наступныя дзеянні:
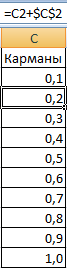
- Давайце створым слупок з кішэнямі, гэта значыць тымі клеткамі, у якіх мы будзем трымаць нашы дыяпазоны. Першы - 0-0,1. Мы фарміруем наступнае з дапамогай гэтай формулы: =C2+$C$2.

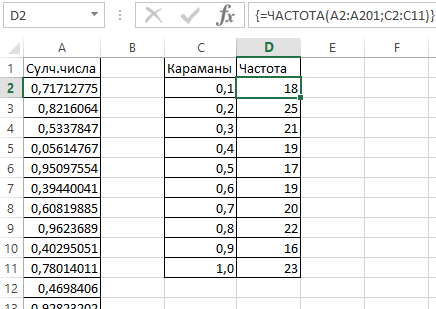
- Пасля гэтага нам трэба вызначыць, як часта сустракаюцца выпадковыя лікі, звязаныя з кожным канкрэтным дыяпазонам. Для гэтага мы можам выкарыстоўваць формулу масіва {=ЧАСТАТА(A2:A201;C2:C11)}.
- Далей, выкарыстоўваючы знак «clutch», мы робім наступныя дыяпазоны. Формула простая =»[0,0-«&C2&»]».
- Цяпер мы складаем дыяграму, якая апісвае, як размеркаваны гэтыя 200 значэнняў.
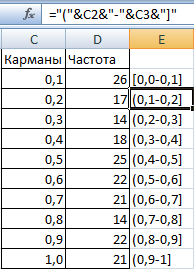
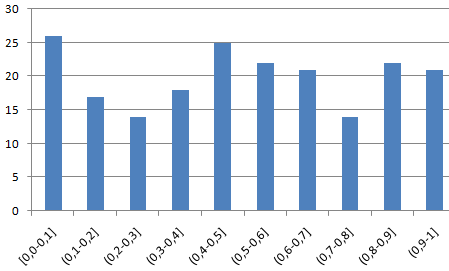
У нашым прыкладзе частата адпавядае восі Y, а «кішэні» — восі X.
ПАМІЖ функцыя
Калі казаць пра функцыі МІЖ СПРАВАЮ, то ў адпаведнасці з яго сінтаксісам ён мае два аргументы: ніжнюю мяжу і верхнюю мяжу. Важна, каб значэнне першага параметру было менш другога. Мяркуецца, што межы могуць быць цэлымі, а дробавыя формулы не ўлічваюцца. Давайце паглядзім, як працуе гэтая функцыя, на гэтым скрыншоце.
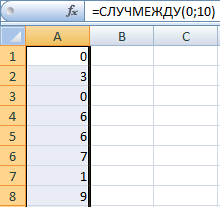
Мы бачым, што дакладнасць можна рэгуляваць з дапамогай дзялення. Вы можаце атрымаць выпадковыя лікі з любымі лічбамі пасля коскі.
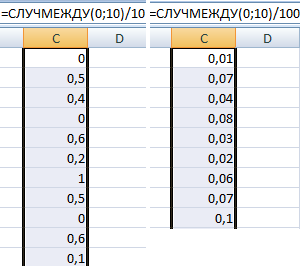
Мы бачым, што гэтая функцыя значна больш арганічная і зразумелая звычайнаму чалавеку, чым папярэдняя. Таму ў большасці выпадкаў можна выкарыстоўваць толькі яго.
Як зрабіць генератар выпадковых лікаў у Excel
А цяпер давайце зробім невялікі генератар лікаў, які будзе атрымліваць значэння на аснове пэўнага дыяпазону дадзеных. Для гэтага ўжываем формулу =ІНДЭКС(A1:A10;ЦЭЛЫ ЛІК(RAND()*10)+1). 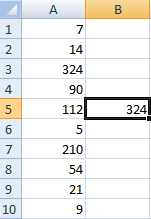
Давайце створым генератар выпадковых лікаў, які будзе генеравацца ад нуля да 10. З дапамогай гэтай формулы мы можам кантраляваць крок, з якім яны будуць генеравацца. Напрыклад, вы можаце стварыць генератар, які будзе ствараць толькі значэнні з нулявым канцом. 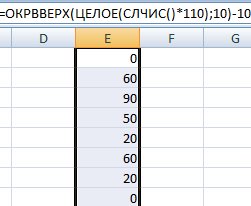
Або такі варыянт. Дапусцім, мы хочам выбраць два выпадковых значэння са спісу тэкставых вочак. 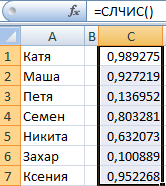
А каб выбраць два выпадковых ліку, трэба ўжыць функцыю індэкс. 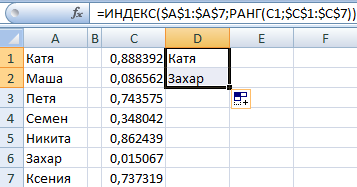
Формула, з дапамогай якой мы гэта зрабілі, паказана на скрыншоце вышэй. =ИНДЕКС(A1:A7;СЛУЧМЕЖДУ(1;СЧЁТЗ(A1:A7))) – з дапамогай гэтай формулы мы можам стварыць генератар для аднаго тэкставага значэння. Бачым, што схавалі дапаможны слупок. Так і вы можаце. 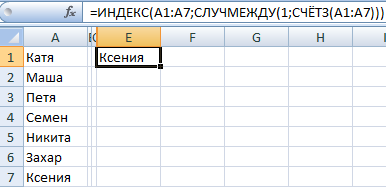
Генератар выпадковых лікаў з нармальным размеркаваннем
Праблема функцыі СЛЧЫС и МІЖ СПРАВАЮ у тым, што яны ўтвараюць набор лікаў, якія вельмі далёкія ад мэты. Верагоднасць таго, што лічба апынецца блізкай да ніжняй, сярэдняй або верхняй мяжы, аднолькавая.
Нармальнае размеркаванне ў статыстыцы - гэта набор даных, у якіх па меры павелічэння адлегласці ад цэнтра на графіку памяншаецца частата, з якой значэнне сустракаецца ў пэўным калідоры. Гэта значыць большасць значэнняў назапашваецца вакол цэнтральнага. Давайце выкарыстоўваць функцыю МІЖ СПРАВАЮ Паспрабуем стварыць набор лікаў, размеркаванне якіх адносіцца да разраду нармальных.
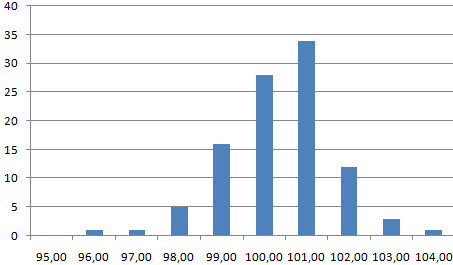
Такім чынам, перад намі прадукт, выраб якога каштуе 100 рублёў. Такім чынам, лічбы павінны генеравацца прыкладна аднолькава. У гэтым выпадку сярэдняе значэнне павінна складаць 100 рублёў. Давайце створым масіў дадзеных і пабудуем графік, у якім стандартнае адхіленне роўна 1,5 рубля, а размеркаванне значэнняў нармальнае.
Для гэтага трэба скарыстацца функцыяй =НОРМОН(SLНУМАР();100;1,5). Далей праграма аўтаматычна змяняе верагоднасці, зыходзячы з таго, што лікі, блізкія да сотні, маюць найбольшы шанец.
Цяпер нам проста трэба пабудаваць графік стандартным спосабам, выбраўшы ў якасці дыяпазону набор згенераваных значэнняў. У выніку мы бачым, што размеркаванне сапраўды нармальнае.
Гэта так проста. Поспехаў.