










У 2016 годзе, выступаючы на Сусветным эканамічным форуме ў Давосе, яго прэзідэнт Клаўс Марцін Шваб казаў пра «Чацвёртую прамысловую рэвалюцыю»: новую эру поўнай аўтаматызацыі, якая стварае канкурэнцыю паміж чалавечым інтэлектам і штучным інтэлектам. Гэта выступленне (як і аднайменная кніга) лічыцца пераломным момантам у развіцці новых тэхналогій. Многім краінам прыйшлося выбіраць, якім шляхам яны пойдуць: прыярытэтам тэхналогій над правамі і свабодамі асобы ці наадварот? Так тэхналагічны пералом ператварыўся ў сацыяльна-палітычны.
Пра што яшчэ гаварыў Шваб і чаму гэта так важна?
Рэвалюцыя зменіць баланс сіл паміж людзьмі і машынамі: штучны інтэлект (AI) і робаты створаць новыя прафесіі, але таксама знішчаць старыя. Усё гэта спародзіць сацыяльную няроўнасць і іншыя ўзрушэнні ў грамадстве.
Лічбавыя тэхналогіі дадуць вялікую перавагу тым, хто з часам зробіць на іх стаўку: вынаходнікам, акцыянерам і венчурным інвестарам. Тое ж самае тычыцца і дзяржаў.
Сёння ў гонцы за сусветнае лідэрства перамагае той, хто мае большы ўплыў у галіне штучнага інтэлекту. Сусветны прыбытак ад прымянення тэхналогіі штучнага інтэлекту ў бліжэйшыя пяць гадоў ацэньваецца ў 16 трыльёнаў долараў, а бНайбольшую долю атрымаюць ЗША і Кітай.
У сваёй кнізе «Звышздольнасць штучнага інтэлекту» кітайскі IT-эксперт Кай-Фу Лі піша пра барацьбу паміж Кітаем і ЗША ў галіне тэхналогій, феномен Сіліконавай даліны і каласальную розніцу паміж дзвюма краінамі.
ЗША і Кітай: гонка ўзбраенняў
ЗША лічыцца адной з самых развітых краін у галіне штучнага інтэлекту. Сусветныя гіганты, якія базуюцца ў Сіліконавай даліне - такія як Google, Apple, Facebook або Microsoft - надаюць вялікую ўвагу гэтым падзеям. Да іх далучаюцца дзясяткі стартапаў.
У 2019 годзе Дональд Трамп даручыў стварыць Амерыканскую ініцыятыву штучнага інтэлекту. Ён працуе ў пяці галінах:
Стратэгія штучнага інтэлекту Міністэрства абароны распавядае аб выкарыстанні гэтых тэхналогій для ваенных патрэб і кібербяспекі. Пры гэтым яшчэ ў 2019 годзе ЗША прызналі перавагу Кітая па некаторых паказчыках, звязаных з даследаваннямі ІІ.
У 2019 годзе ўрад ЗША выдзеліў каля $1 млрд на даследаванні ў галіне штучнага інтэлекту. Аднак да 2020 года толькі 4% генеральных дырэктараў ЗША плануюць укараніць тэхналогію штучнага інтэлекту супраць 20% у 2019 годзе. Яны лічаць, што магчымыя рызыкі тэхналогіі значна вышэйшыя за яе магчымасці.
Кітай імкнецца абагнаць ЗША ў галіне штучнага інтэлекту і іншых тэхналогій. Кропкай адліку можна лічыць 2017 год, калі з'явілася Нацыянальная стратэгія развіцця тэхналогій штучнага інтэлекту. Згодна з ім, да 2020 года Кітай павінен быў зраўняцца з сусветнымі лідэрамі ў гэтай галіне, а агульны аб'ём рынку штучнага інтэлекту ў краіне павінен перавысіць 22 мільярды даляраў. Яны плануюць інвеставаць 700 мільярдаў долараў у разумную вытворчасць, медыцыну, гарады, сельскую гаспадарку і абарону.
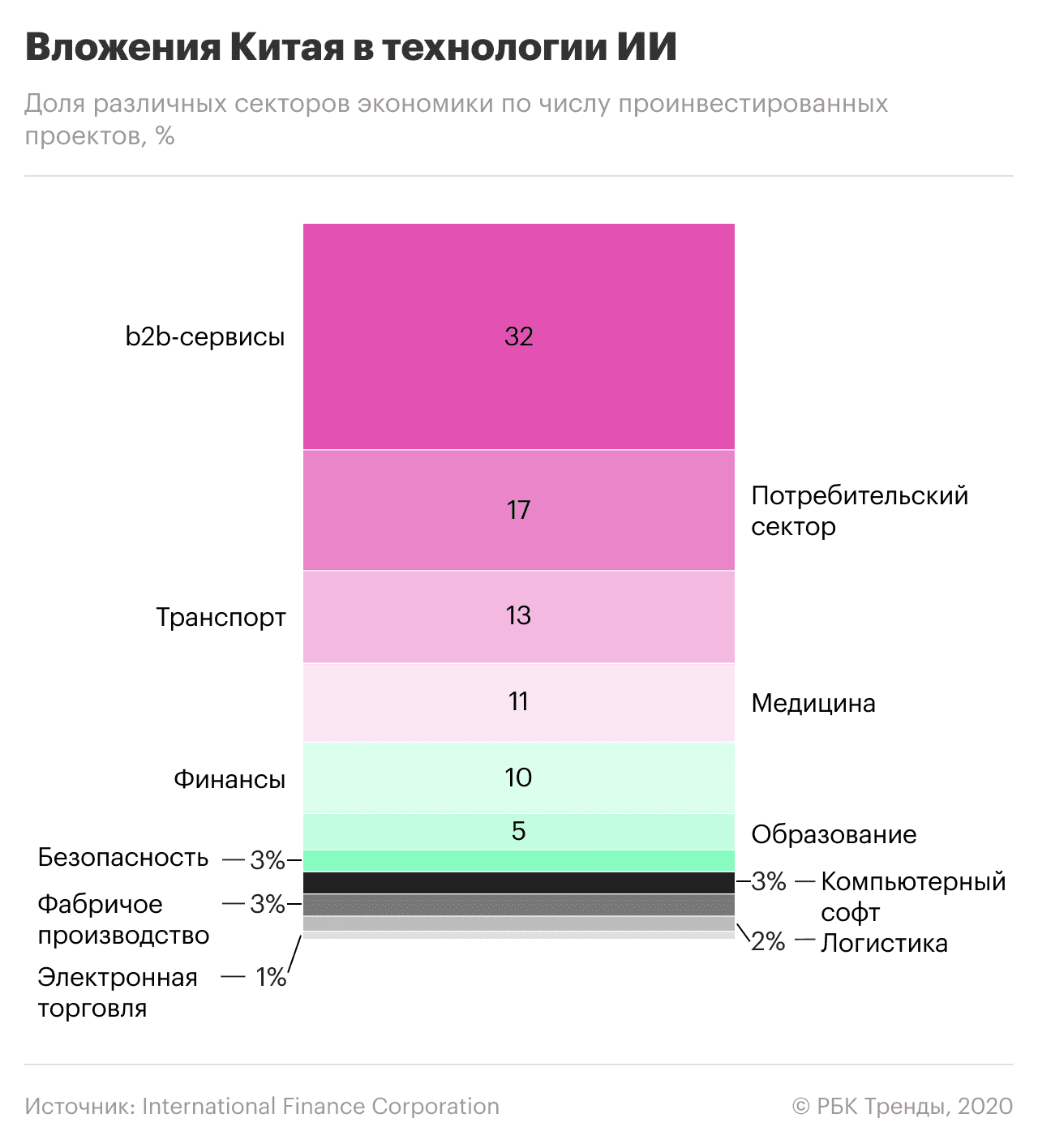
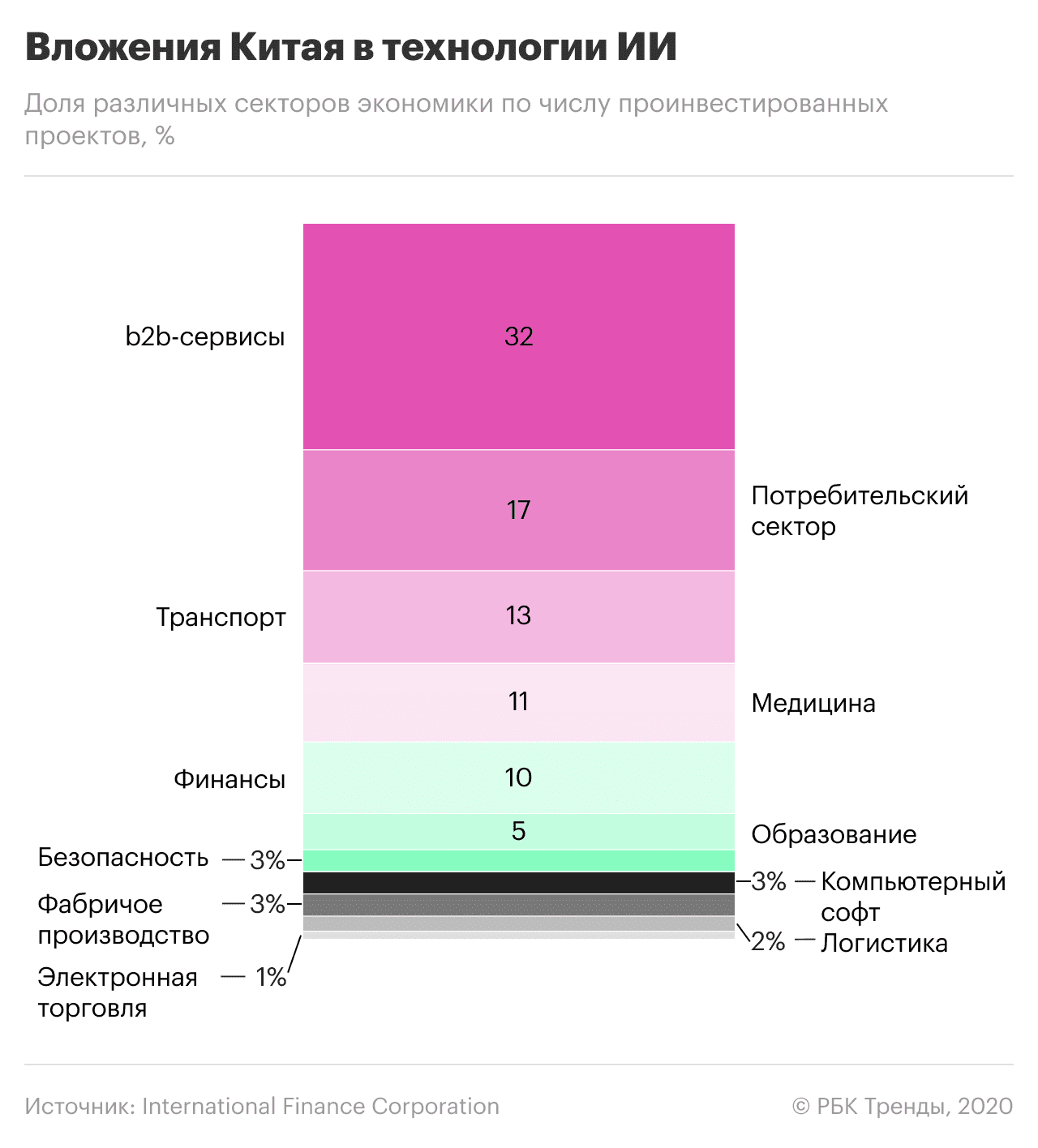
Лідэр Кітая Сі Цзіньпін лічыць ІІ «рухаючай сілай тэхналагічнай рэвалюцыі» і эканамічнага росту. Экс-прэзідэнт кітайскай Google Лі Кайфу звязвае гэта з тым, што AlphaGo (распрацоўка галаўнога офіса Google) перамог кітайскага чэмпіёна па гульнях го Кэ Цзе. Гэта стала тэхналагічным выклікам для Кітая.
Галоўнае, у чым дагэтуль краіна саступала ЗША і іншым лідэрам, — гэта фундаментальныя тэарэтычныя даследаванні, распрацоўка базавых алгарытмаў і чыпаў на аснове ІІ. Каб пераадолець гэта, Кітай актыўна запазычвае лепшыя тэхналогіі і спецыялістаў з сусветнага рынку, не дазваляючы пры гэтым замежным кампаніям канкурыраваць з кітайцамі ўнутры краіны.
Пры гэтым сярод усіх кампаній у сферы штучнага інтэлекту ў некалькі этапаў адбіраюцца лепшыя, якія вылучаюцца ў лідэры галіны. Падобны падыход ужо выкарыстоўваўся ў тэлекамунікацыйнай індустрыі. У 2019 годзе ў Шанхаі пачалі будаваць першую пілотную зону для інавацый і прымянення штучнага інтэлекту.
У 2020 годзе ўрад абяцае выдзеліць яшчэ 1,4 трыльёна долараў на 5G, AI і беспілотныя аўтамабілі. Яны робяць стаўку на найбуйнейшых пастаўшчыкоў хмарных вылічэнняў і аналізу дадзеных - Alibaba Group Holding і Tencent Holdings.
Найбольш паспяховымі сталі Baidu, «кітайскі Google» з дакладнасцю распазнання твараў да 99%, стартапы iFlytek і Face. Рынак кітайскіх мікрасхем толькі за год – з 2018 па 2019 год – вырас на 50%: да $1,73 млрд.
Ва ўмовах гандлёвай вайны і пагаршэння дыпламатычных адносін з ЗША Кітай актывізаваў інтэграцыю грамадзянскіх і ваенных праектаў у галіне ІІ. Галоўная мэта - не толькі тэхналагічная, але і геапалітычная перавага над ЗША.
Нягледзячы на тое, што Кітаю ўдалося абагнаць ЗША па неабмежаваным доступе да вялікіх і асабістых дадзеных, ён па-ранейшаму адстае ў галіне тэхналагічных рашэнняў, даследаванняў і абсталявання. У той жа час кітайцы публікуюць больш цытуемых артыкулаў пра ІІ.
Але каб развіваць AI-праекты, патрэбны не толькі рэсурсы і падтрымка дзяржавы. Неабходны неабмежаваны доступ да вялікіх даных: менавіта яны з'яўляюцца асновай для даследаванняў і распрацовак, а таксама для навучання робатаў, алгарытмаў і нейронавых сетак.
Вялікія дадзеныя і грамадзянскія свабоды: якая цана прагрэсу?
Вялікія дадзеныя ў ЗША таксама ўспрымаюцца сур'ёзна і вераць у іх патэнцыял для эканамічнага развіцця. Нават пры Абаме ўрад запусціў шэсць федэральных праграм вялікіх дадзеных на агульную суму 200 мільёнаў долараў.
Аднак з абаронай вялікіх і асабістых дадзеных тут не ўсё так проста. Пераломным момантам сталі падзеі 11 верасня 2011 года. Мяркуецца, што менавіта тады дзяржава забяспечыла спецслужбам неабмежаваны доступ да асабістых дадзеных сваіх грамадзян.
У 2007 годзе быў прыняты Закон аб барацьбе з тэрарызмам. І з гэтага ж года ў распараджэнні ФБР і ЦРУ з'явіўся PRISM - адзін з самых перадавых сэрвісаў, які збірае асабістыя дадзеныя аб усіх карыстальніках сацыяльных сетак, а таксама сэрвісаў Microsoft, Google, Apple, Yahoo і нават тэлефонных запісы. Менавіта пра гэтую базу казаў Эдвард Сноўдэн, які раней працаваў у камандзе праекта.
Акрамя размоў і паведамленняў у чатах, электронных лістах, праграма збірае і захоўвае дадзеныя геалакацыі, гісторыю браўзераў. Такія дадзеныя ў ЗША значна менш абаронены, чым персанальныя. Усе гэтыя дадзеныя збіраюць і выкарыстоўваюць тыя ж IT-гіганты з Сіліконавай даліны.
Пры гэтым адзінага пакета законаў і мер, якія рэгулююць выкарыстанне вялікіх даных, пакуль няма. Усё заснавана на палітыцы прыватнасці кожнай канкрэтнай кампаніі і фармальных абавязацельствах па абароне дадзеных і ананімізацыі карыстальнікаў. Акрамя таго, у кожным штаце на гэты конт ёсць свае правілы і законы.
Некаторыя дзяржавы ўсё яшчэ спрабуюць абараніць дадзеныя сваіх грамадзян, па меншай меры, ад карпарацый. У Каліфорніі дзейнічае самы жорсткі закон аб абароне дадзеных у краіне з 2020 года. Згодна з ім, інтэрнэт-карыстальнікі маюць права ведаць, якую інфармацыю пра іх збіраюць кампаніі, як і навошта яны яе выкарыстоўваюць. Любы карыстальнік можа запытаць яго выдаленне або забараніць збор. Годам раней ён таксама забараніў выкарыстанне сістэмы распазнання асоб у працы паліцыі і спецслужбаў.
Ананімізацыя дадзеных - папулярны інструмент, які выкарыстоўваюць амерыканскія кампаніі: калі дадзеныя ананімныя, і па іх немагчыма ідэнтыфікаваць канкрэтнага чалавека. Аднак гэта адкрывае перад кампаніямі вялікія магчымасці для збору, аналізу і прымянення даных у камерцыйных мэтах. Пры гэтым на іх больш не распаўсюджваюцца патрабаванні канфідэнцыяльнасці. Такія дадзеныя свабодна прадаюцца праз спецыяльныя біржы і асобных брокераў.
Прыняўшы законы аб абароне ад збору і продажу дадзеных на федэральным узроўні, Амерыка можа сутыкнуцца з тэхнічнымі праблемамі, якія, па сутнасці, закрануць усіх нас. Такім чынам, вы можаце адключыць адсочванне месцазнаходжання на сваім тэлефоне і ў праграмах, але як быць са спадарожнікамі, якія транслююць гэтыя даныя? Цяпер іх каля 800 на арбіце, і адключыць іх немагчыма: такім чынам мы застанемся без інтэрнэту, сувязі і важных даных – у тым ліку здымкаў надыходзячых штормаў і ўраганаў.
У Кітаі з 2017 года дзейнічае закон аб кібербяспецы. Ён, з аднаго боку, забараняе інтэрнэт-кампаніям збіраць і прадаваць інфармацыю аб карыстальніках з іх згоды. У 2018 годзе нават выпусцілі спецыфікацыю па абароне персанальных даных, якая лічыцца адной з найбольш блізкіх да еўрапейскага GDPR. Аднак спецыфікацыя з'яўляецца толькі зводам правілаў, а не законам, і не дазваляе грамадзянам адстойваць свае правы ў судзе.
З іншага боку, закон абавязвае мабільных аператараў, інтэрнэт-правайдэраў і стратэгічныя прадпрыемствы захоўваць частку дадзеных у краіне і перадаваць іх уладам па запыце. Нешта падобнае ў нашай краіне прадпісвае так званы «закон вясны». Пры гэтым кантралюючыя органы маюць доступ да любой асабістай інфармацыі: званкоў, лістоў, чатаў, гісторыі браўзераў, геалакацыі.
Усяго ў Кітаі дзейнічае больш за 200 законаў і правілаў, якія тычацца абароны асабістай інфармацыі. З 2019 года ўсе папулярныя праграмы для смартфонаў правяраюцца і блакіруюцца, калі яны збіраюць даныя карыстальнікаў з парушэннем заканадаўства. Пад дзеянне трапілі і тыя сэрвісы, якія фарміруюць стужку пастоў або паказваюць рэкламу на аснове пераваг карыстальнікаў. Каб максімальна абмежаваць доступ да інфармацыі ў сетцы, у краіне дзейнічае «Залаты шчыт», які фільтруе інтэрнэт-трафік у адпаведнасці з заканадаўствам.
З 2019 года Кітай пачаў адмаўляцца ад замежных кампутараў і праграмнага забеспячэння. З 2020 года кітайскія кампаніі абавязаны пераходзіць на воблачныя вылічэнні, а таксама прадастаўляць падрабязныя справаздачы аб уплыве IT-абсталявання на нацыянальную бяспеку. Усё гэта на фоне гандлёвай вайны са Злучанымі Штатамі, якія ставяць пад сумнеў бяспеку абсталявання 5G ад кітайскіх пастаўшчыкоў.
Такая палітыка выклікае непрыманне ў сусветнай супольнасці. ФБР заявіла, што перадача дадзеных праз кітайскія серверы не з'яўляецца бяспечнай: да іх могуць атрымаць доступ мясцовыя спецслужбы. Услед за ім заклапочанасць выказалі і міжнародныя карпарацыі, у тым ліку Apple.
Сусветная праваабарончая арганізацыя Human Rights Watch адзначае, што ў Кітаі створана «сетка татальнага дзяржаўнага электроннага сачэння і складаная сістэма інтэрнэт-цэнзуры». З імі згодныя 25 краін-членаў ААН.
Найбольш яскравы прыклад — Сіньцзян, дзе дзяржава кантралюе 13 мільёнаў уйгураў — мусульманскай нацыянальнай меншасьці. Выкарыстоўваецца распазнаванне твараў, адсочванне ўсіх перамяшчэнняў, размоў, перапіскі і рэпрэсій. Таксама крытыкуецца сістэма «сацыяльнага крэдыту»: калі доступ да разнастайных сэрвісаў і нават пералётаў за мяжу даступныя толькі тым, хто мае дастатковы рэйтынг добранадзейнасці – з пункту гледжання дзяржслужбаў.
Ёсць і іншыя прыклады: калі дзяржавы дамаўляюцца аб адзіных правілах, якія павінны максімальна абараняць асабістыя свабоды і канкурэнцыю. Але тут, як кажуць, ёсць свае нюансы.
Як Еўрапейскі GDPR змяніў спосаб збору і захоўвання даных у свеце
З 2018 года Еўрапейскі саюз прыняў GDPR - Агульны рэгламент аб абароне даных. Ён рэгулюе ўсё, што звязана са зборам, захоўваннем і выкарыстаннем дадзеных карыстальнікаў у Інтэрнэце. Калі год таму закон уступіў у сілу, ён лічыўся самай жорсткай у свеце сістэмай абароны прыватнасці людзей у інтэрнэце.
Закон пералічвае шэсць прававых падстаў для збору і апрацоўкі даных інтэрнэт-карыстальнікаў: напрыклад, асабістая згода, прававыя абавязкі і жыццёвыя інтарэсы. Ёсць таксама восем асноўных правоў для кожнага карыстальніка інтэрнэт-паслуг, у тым ліку права атрымліваць інфармацыю аб зборы дадзеных, выпраўляць або выдаляць дадзеныя пра сябе.
Кампаніі абавязаны збіраць і захоўваць мінімальны аб'ём даных, неабходных для аказання паслуг. Напрыклад, інтэрнэт-крама не павінна пытацца ў вас аб вашых палітычных поглядах, каб даставіць тавар.
Усе персанальныя даныя павінны быць надзейна абаронены ў адпаведнасці з нормамі заканадаўства для кожнага віду дзейнасці. Акрамя таго, персанальныя дадзеныя тут азначаюць, сярод іншага, інфармацыю аб месцазнаходжанні, этнічнай прыналежнасці, рэлігійных перакананнях, файлы cookie браўзера.
Яшчэ адно няпростае патрабаванне - перанос даных з аднаго сэрвісу на іншы: напрыклад, Facebook можа перанесці вашы фатаграфіі ў Google Photos. Не ўсе кампаніі могуць дазволіць сабе гэты варыянт.
Хоць GDPR быў прыняты ў Еўропе, ён распаўсюджваецца на ўсе кампаніі, якія працуюць у ЕС. GDPR распаўсюджваецца на ўсіх, хто апрацоўвае персанальныя даныя грамадзян і рэзідэнтаў ЕС або прапануе ім тавары ці паслугі.
Створаны для абароны, для ІТ-індустрыі закон абярнуўся самымі непрыемнымі наступствамі. Толькі за першы год Еўракамісія аштрафавала больш за 90 кампаній на агульную суму больш за 56 мільёнаў еўра. Больш за тое, максімальны штраф можа дасягаць 20 мільёнаў еўра.
Многія карпарацыі сутыкнуліся з абмежаваннямі, якія стварылі сур'ёзныя перашкоды для іх развіцця ў Еўропе. Сярод іх быў Facebook, а таксама British Airways і сетка гатэляў Marriott. Але перш за ўсё закон ударыў па малому і сярэдняму бізнэсу: ён павінен падганяць усю сваю прадукцыю і ўнутраныя працэсы пад яго нормы.
GDPR спарадзіў цэлую галіну: юрыдычныя фірмы і кансалтынгавыя фірмы, якія дапамагаюць прывесці праграмнае забеспячэнне і інтэрнэт-сэрвісы ў адпаведнасць з законам. Яго аналагі сталі з'яўляцца ў іншых рэгіёнах: Паўднёвай Карэі, Японіі, Афрыцы, Лацінскай Амерыцы, Аўстраліі, Новай Зеландыі і Канадзе. Дакумент аказаў вялікі ўплыў на заканадаўства ЗША, нашай краіны і Кітая ў гэтай сферы.
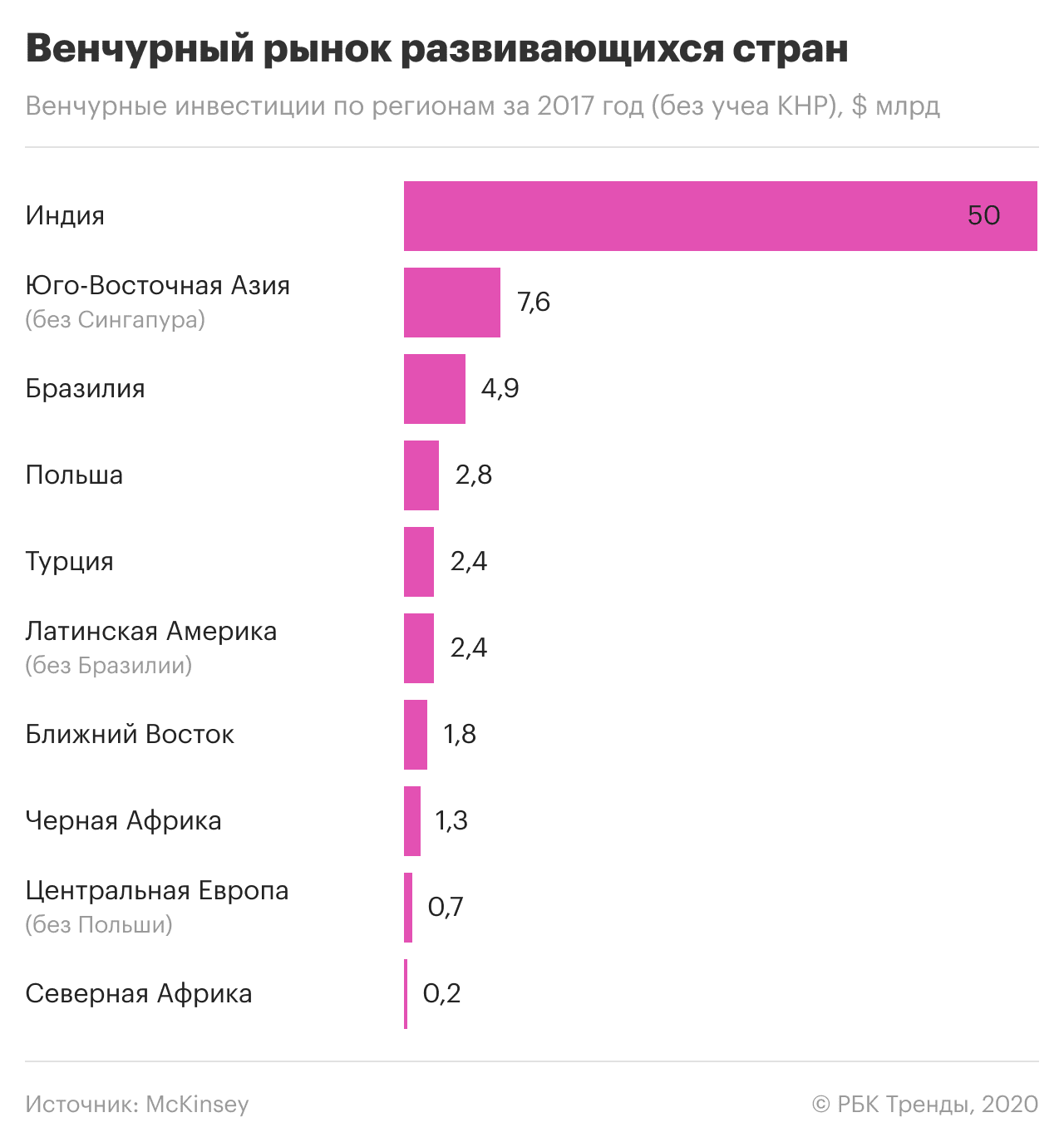
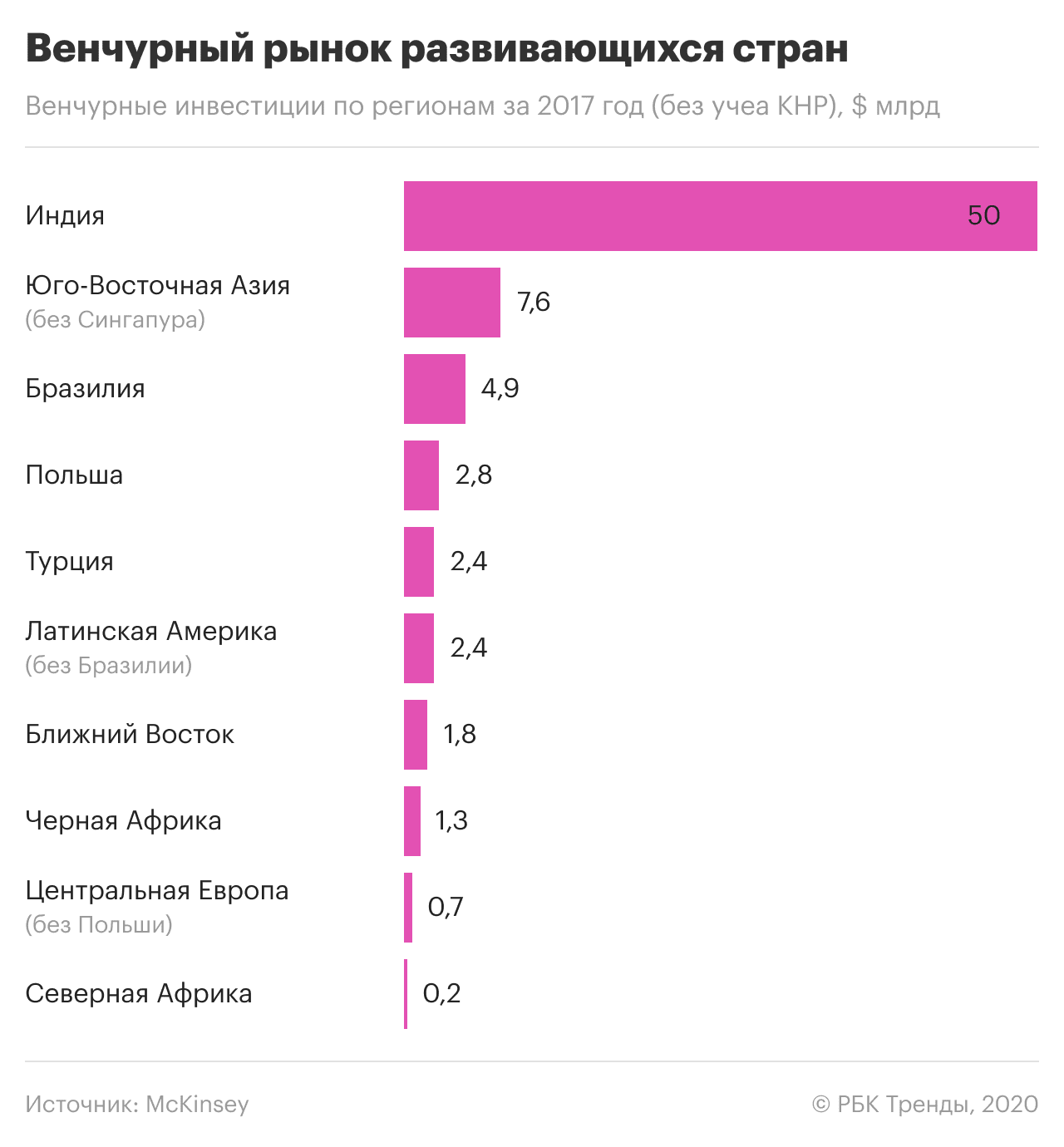
Можа скласціся ўражанне, што міжнародная практыка прымянення і абароны тэхналогій у галіне вялікіх даных і штучнага інтэлекту складаецца з нейкіх крайнасцей: татальнае сачэнне або ціск на IT-кампаніі, недатыкальнасць асабістай інфармацыі або поўная безабароннасць перад дзяржавай і карпарацыямі. Не зусім: ёсць і добрыя прыклады.
ШІ і вялікія дадзеныя на службе Інтэрпола
Міжнародная арганізацыя крымінальнай паліцыі - скарочана Інтэрпол - адна з самых уплывовых у свеце. У яго ўваходзяць 192 краіны. Адной з асноўных задач арганізацыі з'яўляецца складанне баз даных, якія дапамагаюць праваахоўным органам усяго свету прадухіляць і расследаваць злачынствы.
Інтэрпол мае ў сваім распараджэнні 18 міжнародных баз: аб тэрарыстах, небяспечных злачынцах, зброі, скрадзеных творах мастацтва і дакументах. Гэтыя даныя збіраюцца з мільёнаў розных крыніц. Напрыклад, глабальная лічбавая бібліятэка Dial-Doc дазваляе ідэнтыфікаваць скрадзеныя дакументы, а сістэма Edison – падробленыя.
Удасканаленая сістэма распазнання асоб выкарыстоўваецца для адсочвання перамяшчэння злачынцаў і падазраваных. Ён інтэграваны з базамі даных, якія захоўваюць фатаграфіі і іншыя асабістыя даныя з больш чым 160 краін. Яе дапаўняе спецыяльны біяметрычны дадатак, які параўноўвае формы і прапорцыі твару, каб супадзенне было максімальна дакладным.
Сістэма распазнання выяўляе і іншыя фактары, якія змяняюць твар і абцяжарваюць яго ідэнтыфікацыю: асвятленне, старэнне, макіяж і макіяж, пластычныя аперацыі, наступствы алкагалізму і наркаманіі. Каб пазбегнуць памылак, вынікі сістэмнага пошуку правяраюцца ўручную.
Сістэма была ўведзена ў 2016 годзе, цяпер Інтэрпол актыўна працуе над яе ўдасканаленнем. Міжнародны ідэнтыфікацыйны сімпозіум праводзіцца кожныя два гады, а рабочая група Face Expert двойчы на год абменьваецца вопытам паміж краінамі. Яшчэ адна перспектыўная распрацоўка - сістэма распазнавання галасы.
За найноўшыя тэхналогіі ў галіне міжнароднай бяспекі адказваюць Міжнародны даследчы інстытут ААН (UNICRI) і Цэнтр штучнага інтэлекту і робататэхнікі. У Сінгапуры створаны найбуйнейшы міжнародны інавацыйны цэнтр Інтэрпола. Сярод яго распрацовак - робат-паліцэйскі, які дапамагае людзям на вуліцах, а таксама тэхналогіі штучнага інтэлекту і вялікіх дадзеных, якія дапамагаюць прагназаваць і прадухіляць злачынствы.
Як яшчэ вялікія дадзеныя выкарыстоўваюцца ў дзяржаўных паслугах:
NADRA (Пакістан) – база мультыбіяметрычных дадзеных грамадзян, якая выкарыстоўваецца для эфектыўнай сацыяльнай падтрымкі, падатковага і памежнага кантролю.
Упраўленне сацыяльнага забеспячэння ЗША (SSA) выкарыстоўвае вялікія даныя для больш дакладнай апрацоўкі заяў аб інваліднасці і барацьбы з ашуканцамі.
Міністэрства адукацыі ЗША выкарыстоўвае сістэмы распазнавання тэксту для апрацоўкі нарматыўных дакументаў і адсочвання змяненняў у іх.
FluView - амерыканская сістэма адсочвання і барацьбы з эпідэміяй грыпу.
Фактычна вялікія дадзеныя і штучны інтэлект дапамагаюць нам у многіх сферах. Яны створаны на аснове інтэрнэт-сэрвісаў, такіх як тыя, якія апавяшчаюць вас аб заторах і натоўпах. З дапамогай вялікіх даных і штучнага інтэлекту ў медыцыне яны праводзяць даследаванні, ствараюць лекі і пратаколы лячэння. Яны дапамагаюць арганізаваць гарадское асяроддзе і транспарт так, каб усім было камфортна. У нацыянальным маштабе яны дапамагаюць развіваць эканоміку, сацыяльныя праекты і тэхнічныя навінкі.
Вось чаму пытанне аб тым, наколькі вялікія дадзеныя збіраюцца і прымяняюцца, а таксама алгарытмы AI, якія з імі працуюць, так важны. Пры гэтым найважнейшыя міжнародныя дакументы, якія рэгулююць гэтую сферу, былі прыняты зусім нядаўна – у 2018-19 гадах. Да гэтага часу няма адназначнага рашэння галоўнай дылемы, звязанай з выкарыстаннем вялікіх дадзеных для бяспекі. Калі, з аднаго боку, празрыстасць усіх судовых рашэнняў і следчых дзеянняў, а з другога — абарона персанальных даных і любой інфармацыі, якая можа нанесці шкоду чалавеку ў выпадку публікацыі. Таму кожная дзяржава (або саюз дзяржаў) вырашае для сябе гэтае пытанне па-свойму. І гэты выбар, часта, вызначае ўсю палітыку і эканоміку на бліжэйшыя дзесяцігоддзі.
Падпісвайцеся на тэлеграм-канал Trends і будзьце ў курсе сучасных тэндэнцый і прагнозаў аб будучыні тэхналогій, эканомікі, адукацыі і інавацый.